Table of Contents
Introduction
Our project is an analysis of product and service reviews to determine the general overall sentiment expressed by it. Often, a review’s tone may be vague to a reader hoping to understand the reviews of the product. With our model’s analysis, we can supplement a user’s reading in better understanding the overall rating of the review. Amazon’s dataset provides an abundance of reviews and ratings that we can use to train our model. Additionally, our model can use rating values from 1 to 5 to classify a review’s tone as negative, somewhat negative, neutral, somewhat positive, and positive. Regarding an interface for interaction, we plan to construct a simple website to predict the likelihood of a block of test that it has a positive, or negative connotation. We narrated and presented our findings in the Amazon project to a group of our peers in that we found common singular words and n-grams used when describing a project. At the end of the project, we were able to build a prediction model where given a sentence it recommended a star rating from 1 being the worst to 5 being the best for the given sentence.
Goals
Algorithms
Naive Bayes
Naive Bayes is an algorithm that assumes conditional independence from other variables. We use this as a multi classifier to determine what kind of rating a review would get. Additionally it is fairly easier to implement and outperforms other solutions in complex solutions. Since we are trying to rate from a range of 1 to 5, it is easier to modify a standard binary naive bayes classifier into a multi one. Moreover, the weights and labels we use in respect are easier to identify and implement with a bag of words.
Doc2Vec
Doc2Vec is an algorithm that builds on top of Word2Vec to vectorize documents. While Word2Vec only generates vectors for specific words, it does not capture the entire context of a sentence, paragraph, or document. Doc2Vec better matches our use case since each review as a whole corresponds to one context–the rating. Doc2Vec maintains not only the importance of word ordering, but also the labels associated with the documents which is where Word2Vec lacks. An alternative to Doc2Vec is a simple bag of words, but this approach loses all significance behind word ordering.
Logistic Regression with Doc2Vec
Since Doc2Vec generates vectors from each document, each document can be seen as a point in a n-dimensional space (400-dimensional in our project). Logistic regression generates planes in our vector space that separates each of our categorical variables–ratings of 1, 2, 3, 4, and 5. While each cluster will not necessarily be separated perfectly, the notion that Doc2Vec can plot similar sounding documents in roughly similar areas, logistic regression should have at least an interesting performance.
SVM with Doc2Vec
SVM will separate each cluster using linear planes with or without a transformation of our vector space. Since it is relatively unknown how the distribution of each vector will be classified, SVM would provide additional interesting results. The general notion is that SVM tends to work well on text classification.
KNN with Doc2Vec
If the vectors produced by Doc2Vec places similarly rated reviews close to one another, KNN should provide relatively decent accuracy. However, reviews in vectorized form may not necessarily follow this clustering considering the wide variety of diction used especially in online reviews.
Dataset
Our dataset was a compilation of Amazon reviews for electronics, books, movies, and television shows. These were the largest files which contained the most amount of reviews and totaled to 12 gigabytes worth of reviews. Each file was in JSON format which is easily parsed into Python as dictionary objects. After compiling all of the reviews into a single file, we had 536,777 one-star reviews, 599,659 two-star reviews, 1,298,748 three-star reviews, 2,953,129 four-star reviews, and 6,896,449 five-star reviews. This totaled to 12,284,762 reviews. There were also some major problems with our data being internet jargon, punctuation, poor engligh and sarcasm.
Note: The main reason we used such a small dataset was because we did not have enough computing power. Just running Naive Bayes alone took around a 4 days of non-stop running on the local machine.
Models
We chose our set of models for specific reasons. Naive Bayes and SVMs have been known to be good with strong text classification, Doc2Vec turns blocks of text into vectors of numbers, Logistic Regression is generally good at classification problems, and KNN can anlyze the sentiment of nearby vectorized reviews that could be similar and possibly yield good results.
Data Processing
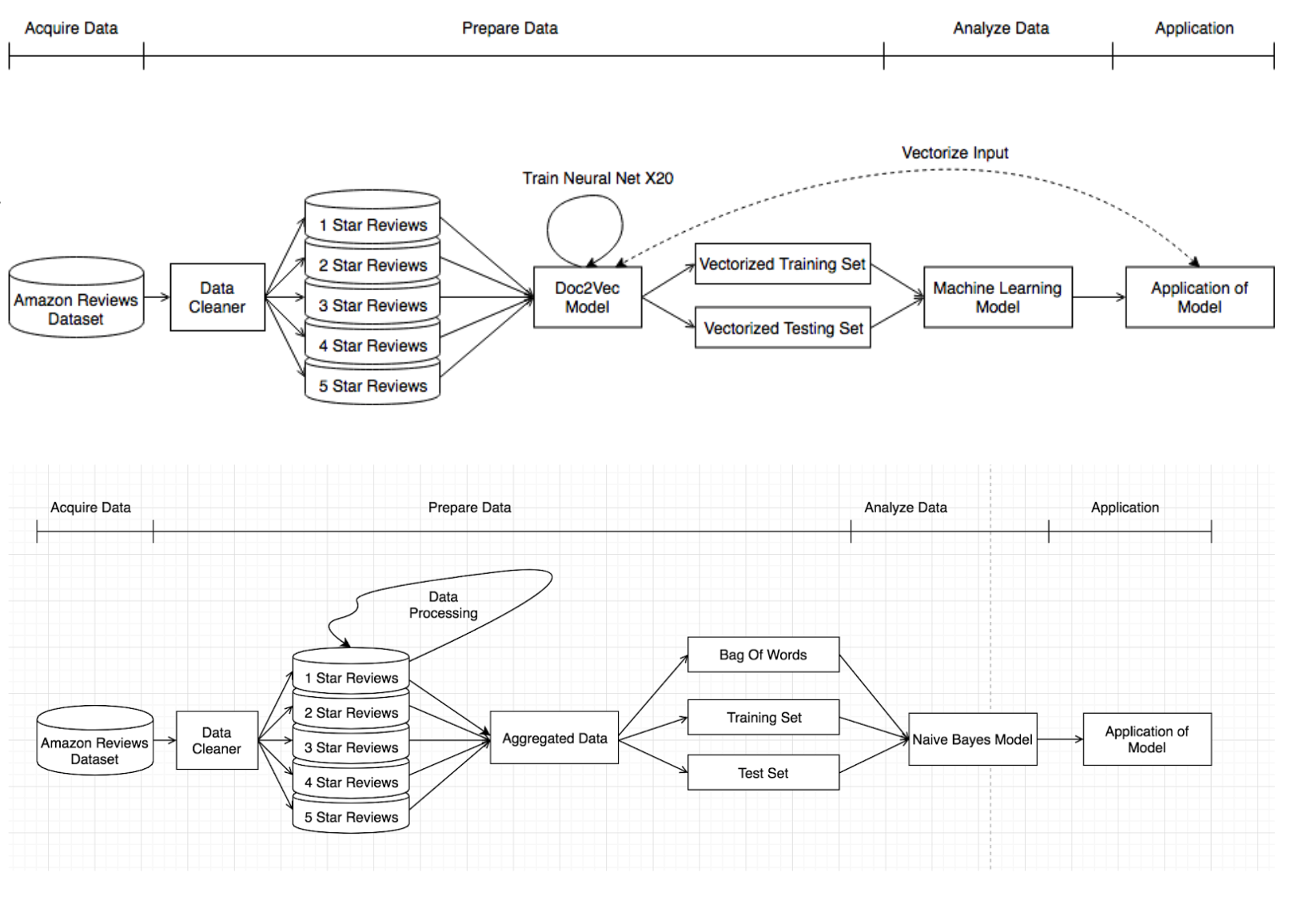
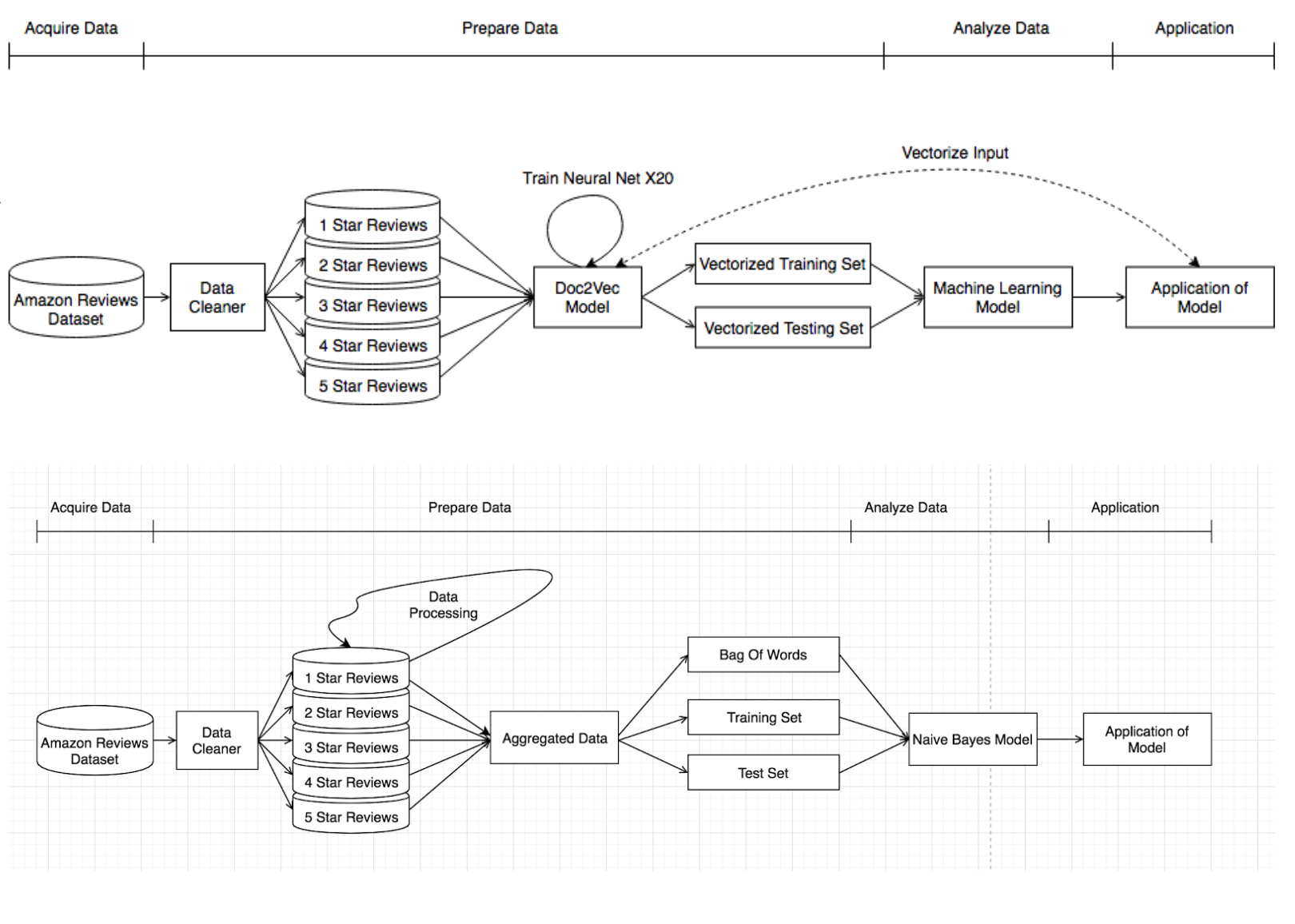
Data preparation was split into multiple parts in order to convert reviews into usable vectors. Since we only needed the ratings and review text of each review, we were able to reduce the size of the data by removing all other fields. Once we had the review text, we had to parse it such that word casing was ignored and that all punctuation was stripped. Punctuation does not contribute a lot to the sentiment overall, so it was not needed. Since we are using online reviews, many of them do not have proper English used and contain a lot of internet jargon. We decided to keep this since internet jargon contributes to the sentiment of the text greatly and outlying words would not necessarily affect our models too much. Since there were unequal amounts of reviews and over 12 million of them, we decided to use a subset of our reviews where we have 75,000 reviews for each rating. This totaled to 375,000 reviews used in total. Using all 12 million reviews would have taken too long and brought too great of a toll onto our laptops.
The “data cleaner” removed all punctuation from each review, and lower cased every single word. The “data cleaner” then split the reviews into five separate files where each file contained reviews of one specific rating.
The Doc2Vec model then took these files and trained itself in twenty epochs to reinforce its neural networks on slightly lower learning rates in each epoch. The result of this was each review converted into a vector of length 400 where 66% of the reviews were kept for training and 33% of the reviews were kept for testing. For other models, we had to apply Doc2Vec to turn our text blocks into numerical vectors. We decided to make each vector of length 400 and train our Doc2Vec model 20 times with lower training rates in each iteration. This allowed us to feed the numerical vectors into multiple machine learning models in a format that was acceptable.
In the Naive Bayes approach (bottom), we used the same five separate files and conducted data preprocessing. We removed stop words, common words and rare words that were present in each of the rating datasets and aggregated them. We then split that information into a Training and Test Set while also creating a Bag of Words. The Bag of Words was constructed by analyzing and compiling the most frequent words present in each rating dataset. We also needed to tokenize our reviews so that determine the word frequency distribution in that set. From there we removed stopwords (I, As, Am, His, A, And, etc..) since they do not contribute to the overall sentiment. Along with stopwords, we also removed a small number of common words and rare words that only appeared once. This allowed us to see the frequency of each word in both the individual rating category and the overall rating category. Both the Training and Test Set were used in conjunction with the Bag Of Words to train the classifier or determine the accuracy of the model. The training test split is 80-20.
Evaluation
To train and test our data, we decided to use a hold out set. For our Doc2Vec models, we used 50,000 reviews from each rating for training and 25,000 review from each rating for testing. For Naive Bayes, we used 10,000 reviews from each rating for training and 2,500 reviews from each rating for testing. We had more than enough data to use, and ended up using only about 3% of what we had originally, so a hold out set was perfectly applicable.
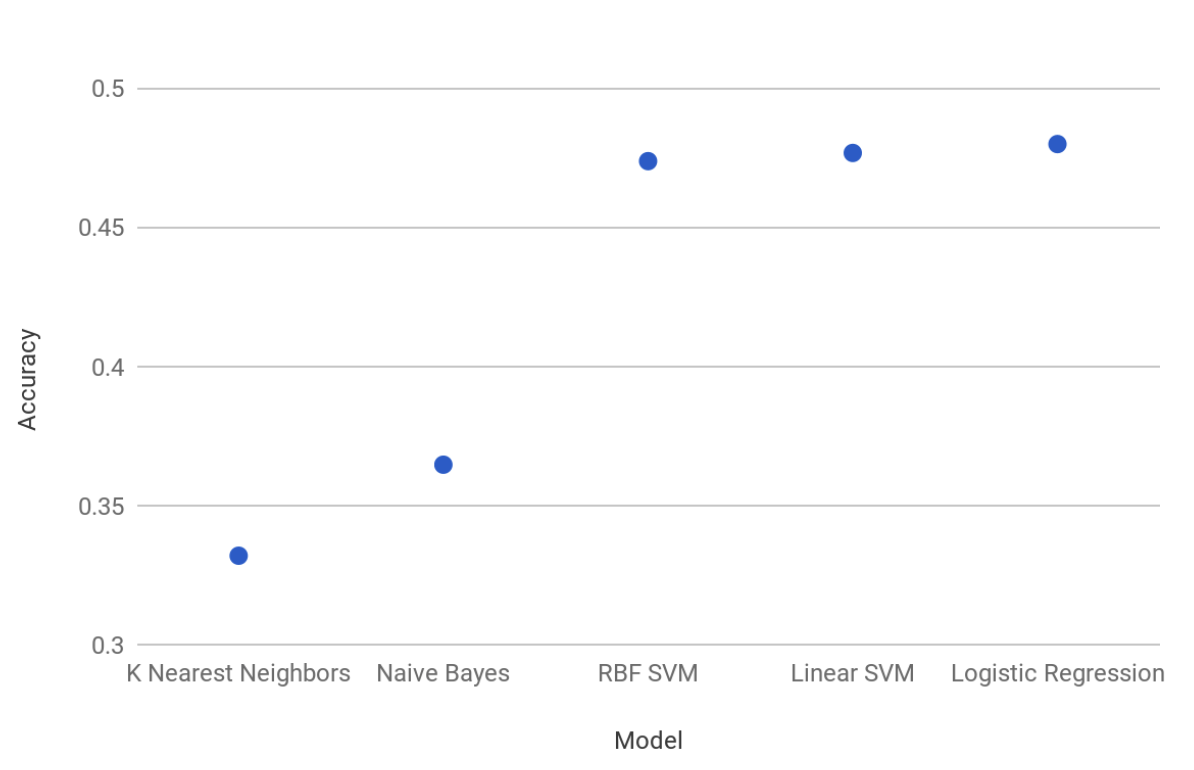
In the image above, these evaluations are based on their accuracy. Going from best to worst is from right to left. From these we decided to continue with the Logistic Regression and linear SVM models since they gave more promising results as seen in the image below.
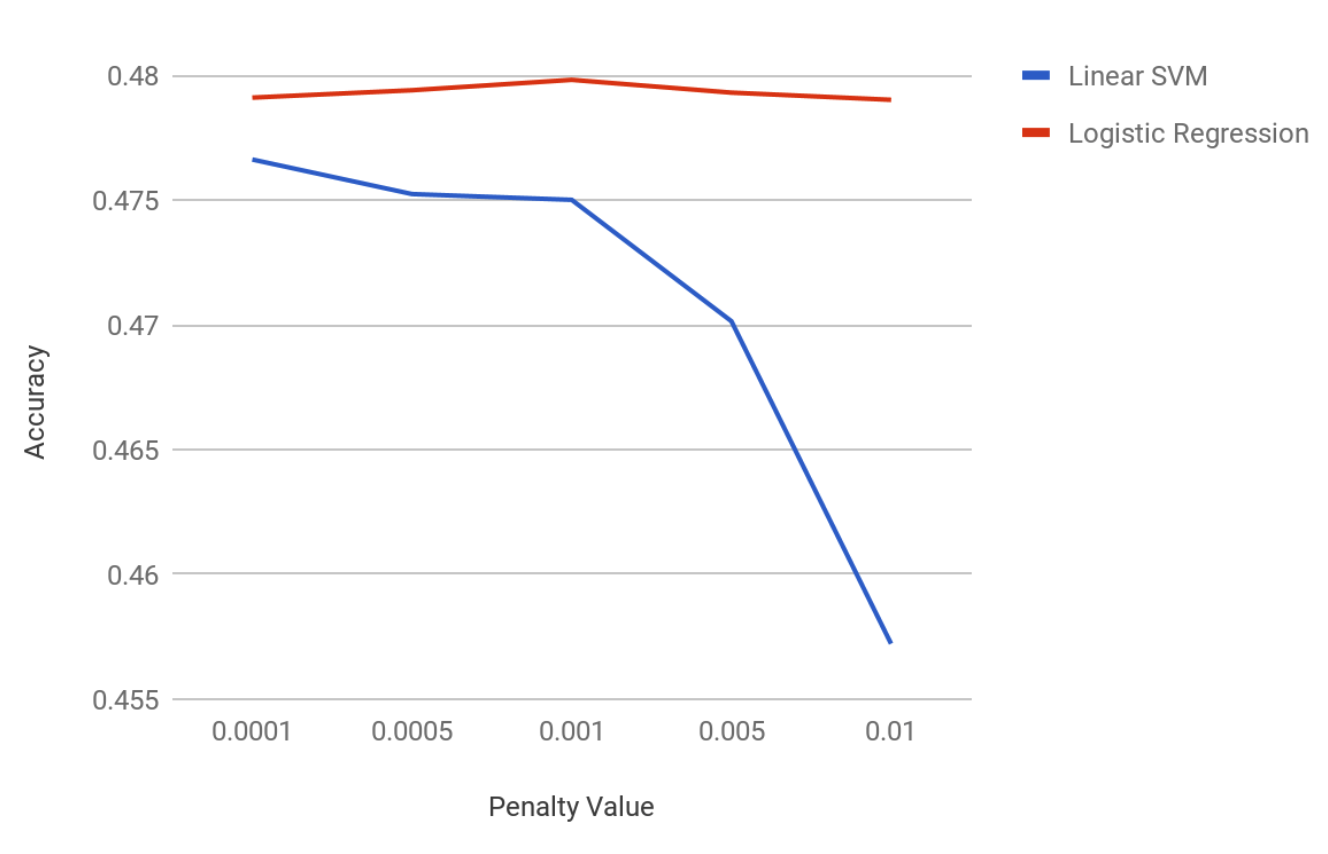
RBF SVM, Naive Bayes, and K Nearest Neighbors use similar datasets since they take much longer to train and test.
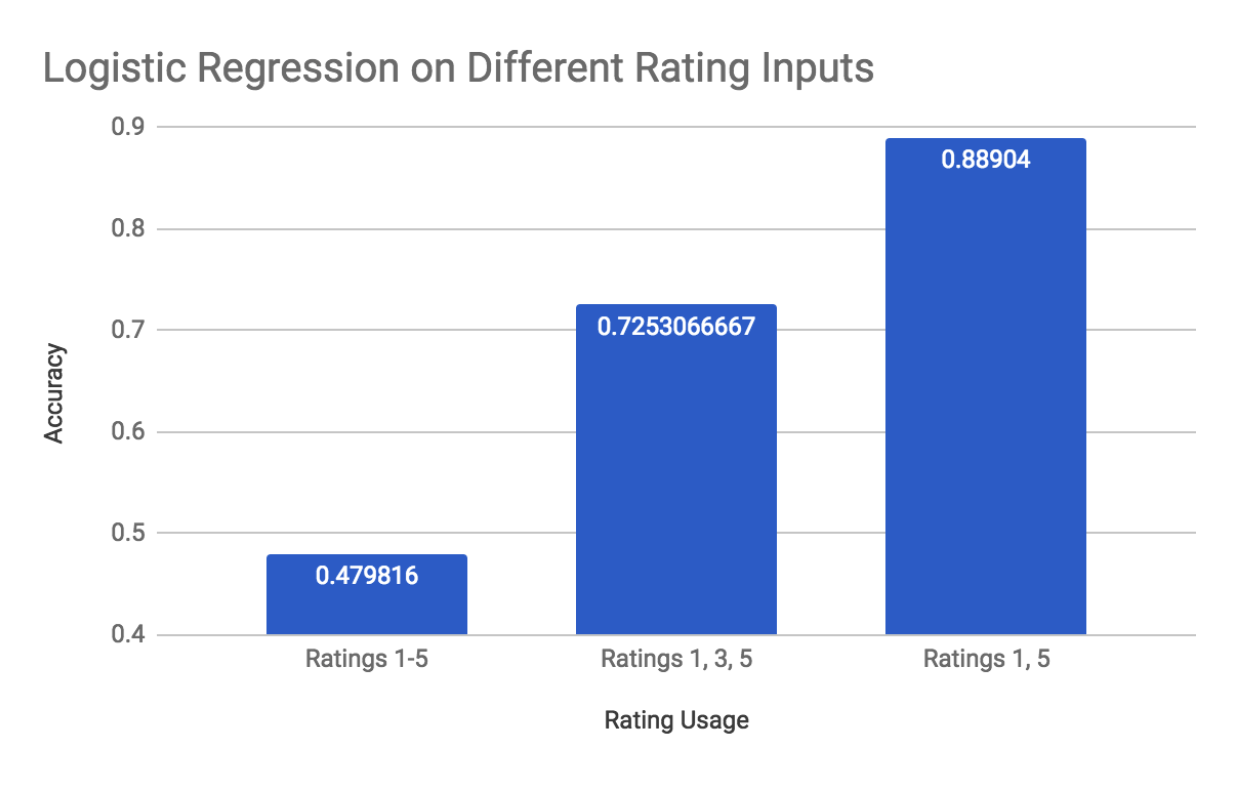
As seen from the previous image, reducing the scope of the predictions result in significantly better accuracies. Classifying only very positive (5) and very negative (1) yields about 89% accuracy. Classifying very positive (5), neutral (3), and very bad (1) yields about 73% accuracy.
Conclusion
The Doc2Vec, Linear SVM, and Logistic Regression model worked well whereas the Naive Bayes and KNN models did not. Non-Linear SVM took too long to train (4+ days…). Some other problems were that the training duration would last for hours at time, thus every samll change in our code had to be retrained. Tokenization was also a debateable topic considering the value of punctuation in English and how to capture their importance. Additionally, more sophisticated tokenization algorithms took far longer. Cleaning the input data to fit the structure was also required for the Doc2Vec since it required a specific object type to be passed into it, that and Doc2Vec is not that well documented or intuitived to use. Looking back, if we had a better understanding of the algorithms, we could have hyper-parameter tuned that resulted in a better performance. Additionally having a larger dataset to use and more computationaly available hardware would of led to quicker and better results.